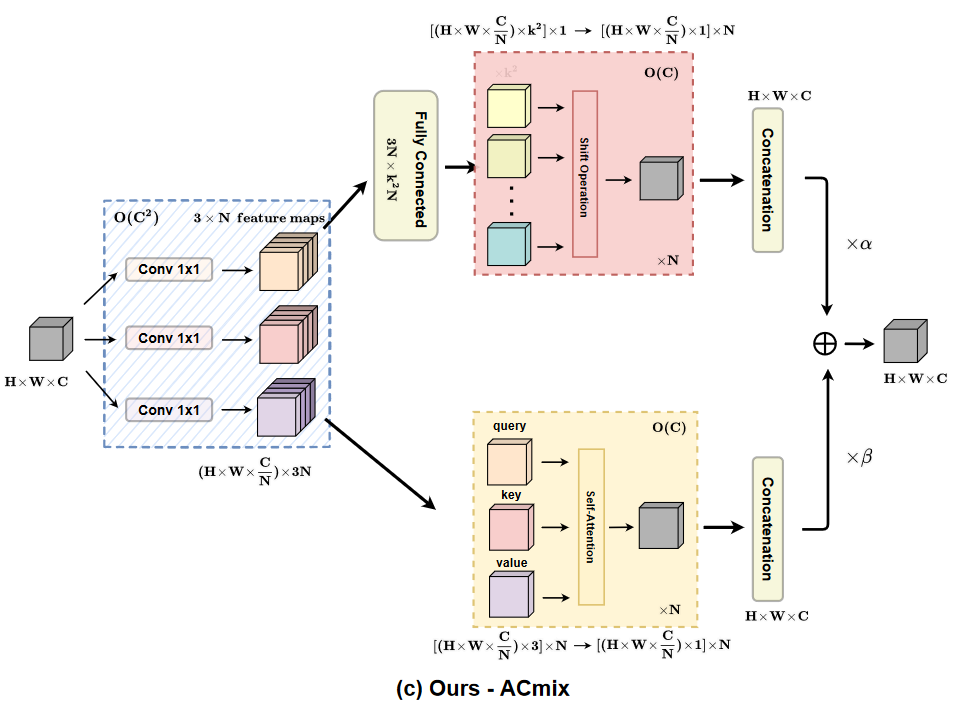
On the Integration of Self-Attention and Convolution
新的视角来融合CNN和self-attention

Unified Training of Universal Time Series Forecasting Transformers
通用时序预测模型,通过展平加变量embedding处理多元时序;多尺度patch size

CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification
dual-branch 多尺度vision transformer。提出一种基于cross-attention的token fusion scheme

MULTIMODAL REPRESENTATION LEARNING BY ALTERNATING UNIMODAL ADAPTATION
交替优化不同模态;通过正交权值修改避免模态遗忘。

Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting
Autoformer。添加decomposition block提取模型中隐藏状态的内在复杂时序趋势。提出Auto-Correlation机制替代self-attention,其考虑sub-series间的相似度能更好的捕捉到趋势性,不仅保证了O(LlnL)的复杂度,也防止了信息的丢失,做到了又快又好。将点对点的attention改进为sub-series之间。