On the Integration of Self-Attention and Convolution
conference: #CVPR 2022
link: https://arxiv.org/abs/2111.14556
==内容不完整,详情见 paper==
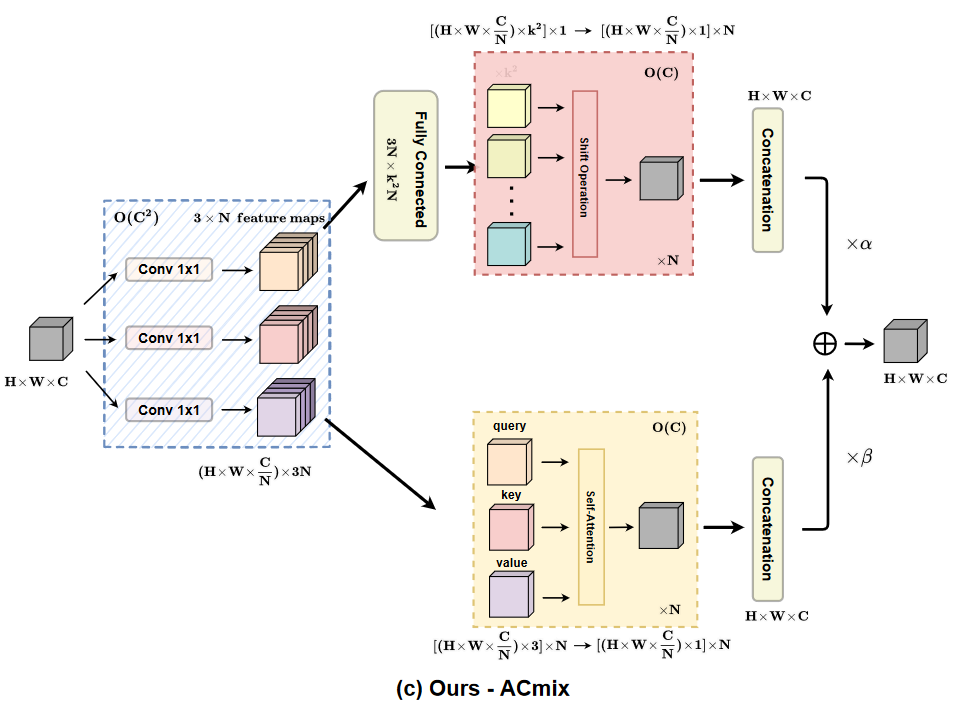
提供一种全新的视角来融合 CNN 和 self-attention
CNN
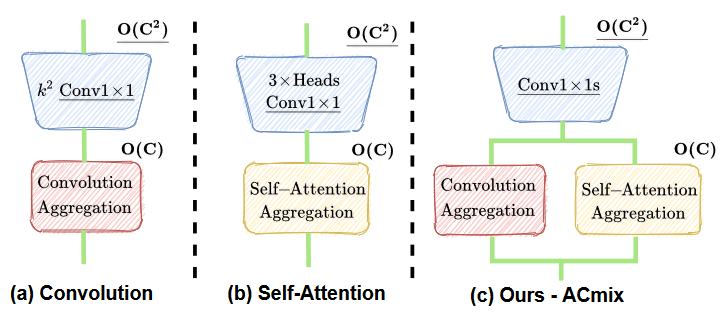
任意卷积核大小为 k 的卷积操作都可以切分成 9 个 1x1 的卷积(stage 1),得到 9 个特征矩阵后,对每个矩阵加入一定的偏移(以 3x3 卷积为例,为保持卷积前后大小不变,往往加入 padding。因此针对每个对应位置的卷积核,比如说最左上角的卷积核,它在 3x3 和 1x1 的卷积操作下得到的结果是不一样的,即这里的偏移)(stage 2)。在这样的分解下,CNN 主要的参数和计算量都集中在 stage 1。
Self-attention
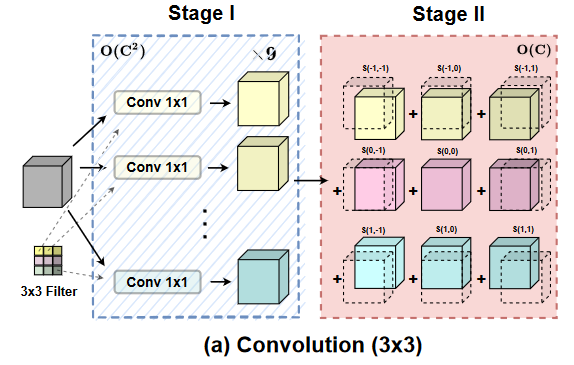
类似的,用 1x1 卷积得到 qkv(stage 1), 然后计算 attention score(stage 2).计算量和参数同样主要集中在 stage 1。
ACmix
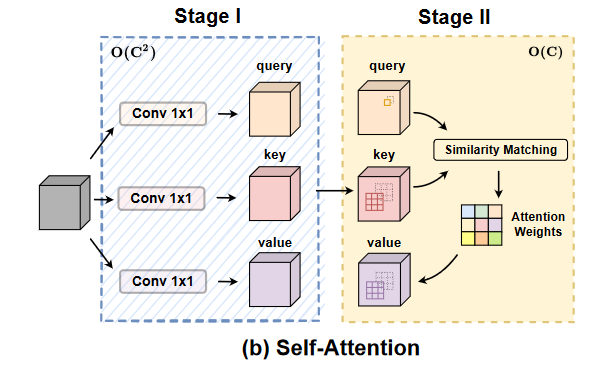
作者将 CNN 和 self-attention 的 stage 1 结合起来,减少了参数和计算量。使用三个 1x1 卷积操作。后接 CNN 时,使用全连接转到 k^2 个卷积核。后接 attention 时,提了个 N 出来,表示多头 attention 的头的数量。最后融合两个结果。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Cloni!
